Purpose
Purpose
this repogitory is run to study reinforcement learning. thus, we apply the tech to control Self-discipline system.

contents
- basic: that is the code to check fundamental reinforcement theology.
- documents: that is the note of reinforcement-learning.
- pole-problem: that is the code to try the feinforcement learning.
- multi-agentict environment.
Using Environment
- Open Gym
- Or Gym
- Muti Agent
my work
I am writing a book on reinforcement learning.
The book is designed for beginners to learn reinforcement learning step by step, covering everything from the basics to practical applications.
It is published on Amazon Kindle, so please feel free to check it out if you are interested.
Amazon.co.jp: 実践!強化学習入門: Pythonで動かしながら理解する AI学習書 (AI関係書籍) eBook : 3 Sons Lover: Kindleストア

My Codes
The repository of my scratch code is stored in next URL:
On the other hand, I have LLM repository also.
Shinichi0713/LLM-fundamental-study: this site is the fundamental page of LLM-mechanism
Please look.
problems
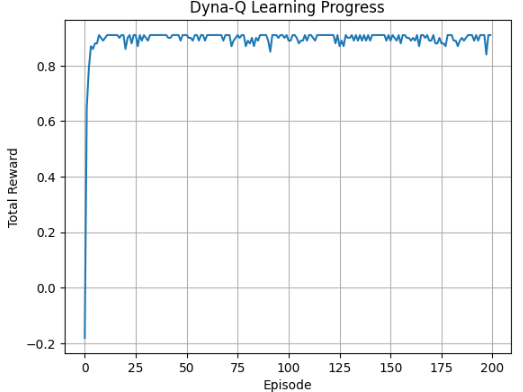
Gird World with Dyna-Q
with using Dyna-Q, train agent to update the model.
below shows trainstion of reward vs episode.
ball cather
this is the behavior of q-learning agent.

pole cart
with using dqn, the motion is completed.

pendulum
this is the behavior of SAC.

luna-landing
this is the behavior of SAC. DDPG can’t work well.

robo-walking
this is the behavior of actor-critic.

BipedalWalkerHardcore
with using sac, the agent gradually walk…
the agent of this walker is based on just fnn model. essencially, the progress of train isn’t proceed well.

at the next, the agent is composed based on transformer. this agent size isn’t large. but, the progress of train proceed as expected. so that, i find ,in RL , the architecture is important. unfortunately, the agent don’t use both legs. this would be owing to short of exploration.


TSP
this is the behavior of PointerNet. not good….

this is the result with using 3 methods.

JSSP
using Actor-critc framework. and, the model is composed with Transformer Network. learn how short the total job become.



imitation learning - behavior clone
when imitation learning is utilized, i check the effect. in this case, reward is improved when using imitation learning.



IRL-GAIL
with using stable_baselines3 and imitation, agent is trained with gail. the reward is given as below.
| trial no | reward |
|---|---|
| 1st | 289.0 |
| 2nd | 295.0 |
| 3rd | 278.0 |
arranging boxes
when using ddqn, ai agent can arrange boxes toward restricted space.
Multi-Agent example
We implemented DQN training using two Rock-Paper-Scissors agents as a multi-agent example problem. We visualized two aspects:
The trend of Agent 1’s average reward (Learning stability).
The trend of Agent 1’s final Q-values (Learned action strategy).
<img src="image/README/1763209192634.png" alt="jssp-3" width="500px" height="auto">
MARL implementation is descripted as below URL:
Reinforce-Learning-Study/miulti-agent/readme.md at main · Shinichi0713/Reinforce-Learning-Study
MARL warehouse
new theme is considering. the environment is displayed as next.
I have been working on the Warehouse Problem, where the task is to have two agents deliver items to designated locations within a warehouse.
Initially, I approached this using QMIX, but I encountered a situation where either both agents would fail to move, or only one of them would operate. I concluded that a lack of exploration was the primary cause.
After switching to HSAC (Heterogeneous Soft Actor-Critic), the agents began to cooperate and function properly. This experience has truly highlighted the critical importance of exploration in reinforcement learning.
with using QMIX, the agents doesn’t work.

with using HASAC, lulti-agent systems have started to operate in coordination with each other.

MARL adventure
This is a cooperative Multi-Agent Reinforcement Learning (MARL) example focusing on information sharing and continuous coordination. The core challenge is to efficiently cover an unknown area by pooling decentralized knowledge.
Environment and Setup
| Item | Details |
|---|---|
| Environment | Anunknown grid map representing a disaster site where critical targets are hidden. |
| Observation | Each drone has avery narrow sensor range (e.g., only adjacent cells), leading to significant local partial observability. |
| Agents | Multiple search drones (or mobile sensor robots). |
| Actions | Movement (Up, Down, Left, Right, Stay). |
| Goal | Maximize map coverage efficiency by minimizing the time required to fully explore the entire map (minimizing unexplored area). |
Learning Objectives and Cooperation Points
- Information Sharing and Distributed Knowledge
- Necessity for Coordination: Without sharing information about previously explored areas, agents will inefficiently perform redundant searches.
- Learning Goal: Agents must learn to integrate their local observations into a common global knowledge map (shared memory) and use this map to choose a strategy that prioritizes moving toward unexplored locations.
- Optimal Coverage and Spatial Load Balancing
- Nature of Coordination: This task emphasizes positive cooperation (“dividing up the unexplored area”) rather than negative cooperation (“avoiding collisions”).
- Learning Goal: The drone swarm must learn a spatial load-balancing strategy: maintaining an appropriate distance from each other to avoid overcrowding while cooperatively segmenting the search area to maximize the overall coverage rate.

Fundamental Knowledge
Roles of Memory in Deep Reinforcement Learning (DRL)
Memory—often referred to as a Replay Buffer or Experience Replay—is essential in DRL for three primary mathematical and practical reasons: stabilizing training and improving efficiency.
1. Breaking Data Correlation (I.I.D. Assumption)
Deep learning models (neural networks) are optimized under the assumption that training data is Independent and Identically Distributed (i.i.d.).
- The Problem: In reinforcement learning, an agent acts sequentially, meaning the “current state” is highly correlated with the “previous state.” Training directly on this sequential data causes the network to overfit to specific temporal patterns, leading to unstable training or divergence.
- The Role of Memory: By storing past experiences in memory and performing random sampling, we break the temporal correlations, satisfying the i.i.d. assumption and stabilizing the learning process.
2. Reuse of Valuable Experiences (Improving Sample Efficiency)
In RL, obtaining a “reward” often requires many steps, making experiences with significant rewards extremely valuable.
- The Problem: If data is discarded immediately after a single action, the agent would need an enormous amount of trial and error to replicate that same “success story.”
- The Role of Memory: Storing rare successes or critical failures allows the agent to learn from them repeatedly, enabling it to become proficient with fewer total interactions with the environment.
3. Enabling Off-policy Learning
Algorithms like DQN (Deep Q-Network) utilize Off-policy learning, which allows the agent to learn from data generated by a version of itself that is different from its current policy (i.e., its past self or other agents).
- The Role of Memory: By looking back at historical records (“I acted this way before and failed”), the agent can evaluate and refine its current decision-making strategy.
MARL
Centralized vs. Decentralized Learning
In Reinforcement Learning, “Centralized Learning” and “Decentralized Learning” refer to structural differences in “who processes the information and where the command center for learning is located.”
The following outlines their characteristics within the context of Multi-Agent Reinforcement Learning (MARL).
1. Centralized Training
This style involves collecting data (observations, actions, rewards) from all agents into a single location to train a single, massive intelligence.
- Mechanism: Learning is based on a “Global State” that integrates information from all agents. To use a football (soccer) analogy, it is like a manager overseeing the entire pitch and giving synchronized instructions to all players.
- Pros: * Directly learns complex interactions between agents (e.g., “Since Agent A moved right, I will move left”).
-
Theoretically, it is the most likely to reach an optimal global solution.
- Cons: * Curse of Dimensionality: As the number of agents increases, the combinations of information grow exponentially, making computation unfeasible.
- Execution Constraints: Since it assumes access to everyone’s information during training, it often requires constant communication between all agents during execution.
2. Decentralized Training
This is a style where each agent learns independently based solely on its own experience.
- Mechanism: Other agents are treated as “part of the environment” (like moving obstacles), and each agent updates its network individually.
- Pros: * High scalability because the computational load is distributed per agent.
-
Resilient to privacy concerns and communication limits since interaction with others is not required for training.
- Cons: * Non-stationarity Problem: Because others change their behavior while an agent is learning, the “rules of the world” appear to change arbitrarily from the AI’s perspective, making learning highly unstable.
- Cooperative behavior relies on chance, making high-level coordination difficult to achieve.
3. Hybrid: Centralized Training, Decentralized Execution (CTDE)
Currently the most popular approach for tasks like cooperative drone control, CTDE combines the best of both worlds.
- Concept: “Practice (Training) involves everyone reviewing game tapes together to reflect, but the Match (Execution) is handled by each individual’s judgment.”
- Features: * Training: Centralized training is performed, refining the “Critic” by considering the actions of others.
-
Execution: Decentralized execution is performed, where the “Actor” acts quickly based only on its own local sensor data.
- Representative Examples: QMIX, MADDPG.
Summary Comparison
| Feature | Centralized | Decentralized | CTDE (Hybrid) |
|---|---|---|---|
| Data Aggregation | Always centralized | Distributed per agent | Centralized only during training |
| Learning Stability | High (Global view) | Low (Others are moving) | Medium to High (Balanced) |
| Execution Autonomy | Low (Requires comms) | High (Operates alone) | High (Operates alone) |
| Primary Use Cases | Small-scale precision control | Large-scale independent envs | Multi-drone coordination |
Conclusion: Regarding the choice between centralized or decentralized, the modern MARL consensus is that CTDE (Centralized Training, Decentralized Execution) is the most efficient and practical solution.
MARL Learning Methodologies
The major frameworks for cooperative learning in MARL are categorized into three types based on how they handle information and the learning process. While CTDE is the current standard, here are the characteristics of each:
1. Decentralized Training, Decentralized Execution (DTDE)
The simplest form where each agent treats others as “part of the environment” (like moving walls) and learns/executes independently.
- Mechanism: Each agent runs a single-agent algorithm (e.g., DQN, PPO) independently (Independent RL).
- Pros: Simple algorithm; the structure remains the same regardless of the number of agents.
- Challenges: Environment instability (non-stationarity) makes convergence difficult.
2. Centralized Training, Centralized Execution (CTCE)
Treats all agents as one “giant AI,” processing all observations and actions collectively.
- Mechanism: All observations are merged into one input vector, and all actions are defined in one giant joint action space.
- Pros: Theoretically can learn the most optimal cooperative combinations.
- Challenges: Curse of dimensionality makes computation impossible as agents increase; requires constant communication during execution.
3. Centralized Training, Decentralized Execution (CTDE)
The current de facto standard. It shares information only during training and maintains independence during execution.
- Mechanism: * Training (Centralized): A Critic or Mixing Network “cheats” by looking at the states and actions of all agents to accurately evaluate each action.
-
Execution (Decentralized): Each agent uses only its own network (Actor) to decide actions based on local info.
- Representative Methods: MADDPG (Individual critics see others’ actions), QMIX/VDN (Individual values integrated into a team value).
- Pros: Stable learning; works in environments with weak communication infrastructure (e.g., field-deployed drones).
4. Communication-based Learning
A framework where agents encourage cooperation by sending “messages” to one another.
- Mechanism: Includes a network layer to exchange vectorized information (communication protocols) before selecting an action.
- Pros: Allows agents to know the status of teammates outside their field of view, enabling high-level coordination.
- Representative Methods: CommNet, DIAL.
5. Hierarchical / Role-based Learning
Dividing agents into a “Manager” (commander) and “Workers” (executors), or assigning specific “Roles.”
- Mechanism: Separates the AI that sets long-term goals from the AI that performs specific operations (e.g., drone movement).
- Pros: Efficiently learns complex, long-term tasks.
- Representative Methods: ROMA (Dynamic role learning).
For more detail, please come in here.
cite
in this repogitory, oss ‘pygame-learning-environment’ is used. https://github.com/ntasfi/PyGame-Learning-Environment
deep mind archives!
very nice site!
References
when studying RL, I refer to any other web-site. show the reference site.
AI compass this site indicates many ai knowledge with insight.
星の本棚 this site shows nice tips about reinforcement learning.
blog
I publish technical articles focused on Reinforcement Learning related technics on my blog. Feel free to visit and have a read.